상태 공간 트리 (State-Space Tree)
문제 해결 과정의 중간 상태를 각각 한 노드로 나타낸 트리를 상태 공간 트리(State-Space Tree)라고 한다.
이러한 상태 공간 트리를 탐색하는 방식들에 대해서 이야기 하고자 한다.
1. 백트래킹 (Backtracking)
백트래킹은 주어진 상태 공간 트리를 트리의 루트에서 시작해서 DFS 방식으로 탐색을 해 나가는 것이다.
탐색을 하다가 더 갈 수 없으면 왔던 길을 되돌아가 다른 길을 찾는다고 해서 이런 이름이 붙었다고 한다.
대표적으로 미로 찾기 문제와 색칠 문제가 있다.
미로 찾기 문제
만약 우리가 미로에 갇히게 되면 어떻게 탈출해야할까?
갈 수 있는곳을 일단 가보고, 막다른길이 있다면 왔던길을 되돌아와
가보지 않은 길을 선택하는 행동을 출구가 나올때 까지 반복할 것이다.
미로 -> 상태 공간 트리
막다른 길 = 리프노드
경로를 선택할 수 있는 지점 = 리프노드와 루트노드를 제외한 노드
미로를 상태 공간 트리로 표현했을 때 이를 DFS로 탐색하고, 출구노드를 발견하면 탐색을 종료하는것은
위에서 언급한 우리가 미로를 탈출하는 방법과 그대로 대응하는것으로 생각 할 수 있다.
성능은 어떨까?
당연하겠지만
운이 좋으면 매 선택의 기로마다 올바른 선택을해서 바로 미로를 탈출할 수도,
운이 나쁘면 모든경우를 다 탐색하게 될 것이다.
2. 한정분기 (Branch and Bound)
어떤 문제의 해를 상태 공간 트리를 모두 탐색해서 찾아내려고 할 때
경우의수가 엄청나게 크다면 현실적인 시간내에 해를 찾을 수 없다.
경우의수가 엄청나게 많은 문제의 상태 공간 트리를 보면
꽤 많은 서브트리들이 방문하지 않아도 될법 하다는것을 발견 할 수 있다.
예를들어 TSP문제에서 어떤 부분 경로의 길이가 지금까지 찾아놓은 가장 좋은 해를 초과한다면
그 경로에서 더 진행 할 필요가 없다는것이다.
이렇게 상태 공간에서 탐색할 정점들을 판단기준(지금까지 찾은 가장 좋은 해보다 더 좋아질 수 있는지)에 따라 제외해 나가는것을 가지치기(Pruning)이라고 한다.
얼마나 성능이 향상될까?
초기에 꽤 좋은 품질의 해를 가지고 시작하면 시간이 많이 절약된다.
가지치기의 기준이 엄격해 정말 좋은 해를 얻을 수 있을법한 노드들만 남기고 모두 제외 해버리는 것이다.
하지만 최초로 찾은 해의 품질이 매우 나쁠경우
그 해를 기준으로 가지치기를 하는것은 하나마나한 행위일 것이고, 최악의경우 거의 모든 정점을 탐하게 될 수도 있다.
따라서 최초로 찾은 해의 품질이 높기만을 빌어야 하는데,
해결하고자 하는 문제에 대해 다양한 방법으로 시도한 결과가 알려져 있으면,
그 중 가장 좋은 해를 최초의 기준해로 삼아서 시작하는 것이 방법일 것이다.
TSP에서 한정분기
어떻게 TSP에서 한정분기를 통해 탐색할 경우의 수를 줄일수 있을까?
상태 공간 트리에서 매 노드마다 "탐색을 하면 할수록 아무리 작아도 이것보단 클것이다" 하는 하한값을 계산하고,
여태껏 찾은 가장 좋은해보다 하한값이 크다면 해당 노드를 제외해 버리는 것이다.
-
이 문제에서 하한값을 구하는 간단한 방법
각 정점에서 다른 정점에 이르는 간선들의 길이 중 가장 짧은 값을 구해놓는다.
아직 연결되지 않은 정점들에 대해서 위 값을 모두 더해준다.
위와같은 간선조합을 한다고 해도 합법적인 사이클이 될 가능성은 매우 낮다
따라서 대다수의 경우는 위 방법처럼 더한 값보다 클것이고,
매우 희박한 확률로 위 방법처럼 더한 값과 같을것이다.
3. A* 알고리즘 (A* search algorithm)
A*알고리즘은 그래프의 시작점에서 도착점에 이르는 최단 경로를 찾는 알고리즘이다. 그래프에서 최단 경로 문제에 적용되기도 하지만 상태 공간 트리도 그래프의 일종이므로 적용될 수 있고, 실제로 상태 공간 트리의 탐색에서 A*알고리즘을 더 많이 사용한다.
최적 우선 탐색(Best-First Search)
최적 우선 탐색이란 그래프에서 탐색하는 방법 중 하나로, 각 정점이 각자의 매력 함수 값 g(x)를 갖고 있는 경우에 적용된다. 시작점에서부터 출발하여 지금까지 방문하지 않은 정점 중 g(x)값이 가장 매력적인 것부터 방문하는 탐색 방법이다.
다익스트라 알고리즘은 d[x]값이 g(x) 값이 되는 최적 우선 탐색이다 (S집합에 정점이 추가될때마다 d[x]가 변화한다.)
프림 알고리즘은 정점 x를 연결하는 최소 비용이 g(x)인 최적 우선 탐색이다.
1) 최단 경로 찾기 문제
-
다익스트라 알고리즘
다익스트라 알고리즘은 시작점만 있고 목적점은 명시하지 않고,
시작 정점 ~ 모든 정점 간의 최단 거리를 구한다.
단 하나의 목적점에 대한 최단거리를 찾기 위해
다익스트라 알고리즘을 수행하다가, 목적점에 해당하는 최단 경로를 발견하는 순간 탐색을 종료하는 방법을 사용하면
성능상의 낭비가 있을 수 있다.
-
어떤 정점을 선택해야 할까?
지금까지 방문하지 않은 정점 중 g(x)값이 가장 작은 정점을 선택하면 최단 경로를 찾는것을 보장할 수 없다.
최단 경로 탐색 문제가 그리디 문제가 아닌 까닭이다.
(지금 당장 좋아보이는 선택을 하더라도 그 이후의 경로가 멀리 돌아가는 경로일 수 있다.)
-
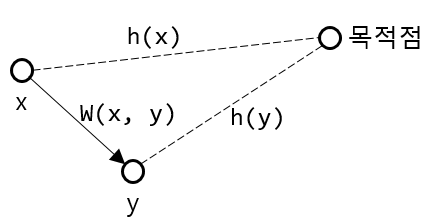
추정거리
따라서 A*알고리즘을 통해 시작점 ~ 목적점까지의 최단 경로를 구할 때 g(x)뿐만 아니라
정점 x에서 목점점까지 추정 잔여 거리 h(x)를 함께 고려하여 구한다.
이 추정 거리 h(x)는 x에서 목적점까지 실제 최단 거리보다는 크지 않아야 한다.
다음 정점을 선택할 때 g(x)+h(x)가 가장 작은 정점을 선택 한다면
h(x)가 올바른 선택 기준이 되기 위해서는 현 시점에서 실제 남은 거리를 정확하게 알 수는 없지만,
실제 남은 거리가 아무리 작아져도 추정거리 h(x) 보다는 크거나 같아야함은 자명하다
-
A* 알고리즘이 최적해를 보장하는 조건
- 추정 거리 h(x)가 실제 남은 거리보다 크지 않다
- 모든 정점 쌍(x,y)에 대하여 h(x) <= w(x,y) + h(y)를 만족한다.
(정점x ~ 목적점 간의 직선거리를 h(x)로 사용한다면 위 조건을 만족할 수 있을 것이다.)
목적점을 명시하지 않는 다익스트라 알고리즘의 경우 목적점까지의 추정거리없이,
g(x)만을 이용해 최단 거리를 구하기 때문에
우리가 찾고자 하는 목적점까지의 최단 경로에 포함 될리가 없는 정점들 까지 탐색하게 된다.
(목적점이 없으므로 목적점까지의 추정 거리를 구하는것이 애초에 말이 되지 않는다. 그리고 더 좋은 g(x)를 발견하면 갱신해야 하므로 당연히 모든 정점을 탐색해야 한다.)
-
다익스트라 알고리즘과의 관계
이제 A*알고리즘과 다익스트라 알고리즘의 관계를 살펴보면
다익스트라 알고리즘은 h(x) = 0인 A*알고리즘 이라고 볼 수 있다.
h(x) = 0 은 실제 남은 거리보다 크지 않아야 된다는 조건을 만족하므로 A*알고리즘이라고 볼 수 있는것이다.
따라서 다익스트라 알고리즘이 최적해를 보장한다는것은 이런 관점에서도 확인할 수 있다.
하지만 h(x) = 0 은 무의미한 추정치이고, 찾고자 하는 목적점이 있다면 직선거리 등을 h(x)로 활용해서 효율성을 증가시켜야 겠다.
2) TSP
임의의 부분 경로 x에서 지금까지 지나온 경로의 길이를 g(x), 잔여 경로의 추정치를 h(x)로 놓고
g(x) + h(x) 값이 작은 값부터 선택해 나가다가 리프노드를 만나면 종료한다.
부분 경로를 포함하는 해밀토니안 사이클의 추정치 h(x)를 구하는 방법은 한정 분기 알고리즘에서 사용한 방법과 똑같다. 즉, 각 정점에서 나가는 간선 중 가장 짧은 간선들을 사용하여 잔여 경로의 추정치로 삼는다.
최단 경로 찾기 문제와 같은 경우는 모든 정점에 대해 미리 h(x)를 계산해둘 수 있었다.
하지만 일반적인 상태 공간 트리의 탐색에서는 h(x)값을 만들어가면서 탐색이 진행된다.
-
구체적인 동작 방식을 살펴보자
앞서 TSP 에서는 미리 h(x)를 구해놓을 수 없다고 했다.
따라서 아래와 같은 방법으로 방문과 하한값 계산을 반복하며 탐색해야 한다.
큐에서 노드 선택&방문 -> 자식노드들의 h(x) 계산 -> 자식노드들을 하한값을 기준으로 큐에 삽입 -> ....반복
루트노드에서 방문할 수 있는 노드(시작 정점과 간선으로 연결된 정점)들의 하한값을 구하고,
그 노드들을 하한값을 기준으로 우선순위 큐(방문 할 노드 목록)에 삽입한다.
우선순위 큐(방문 할 노드 목록)에서 가장 하한값이 낮은 노드를 선택하고(만약 하한값이 같은 노드가 있다면 깊이가 가장 깊은 노드를 선택한다), 그 노드에서 방문할 수 있는 노드들의 하한값을 구하고, 하한값을 기준으로 우선순위 큐에 삽입한다.
위와 같은 과정을 반복하다 리프노드를 만나면 종료한다.
-
진짜로 최적해를 찾게 될까?
상태 공간 트리를 탐색하다가 리프노드를 만나서 종료한 시점에서
내가 찾은 리프노드를 제외한 모든 노드들을 두 종류로 생각해 볼 수 있다.
- 우선순위 큐에 들어있는 노드
- 우선순위 큐에 들어있지 않은 노드
1번 노드의 경우에는 하한값이 내가 찾은 리프노드보다 같거나 클것이다.
노드의 하한값이 같은 경우에는 깊이가 더 깊은 노드를 선택한다고 했으니
결국 그 노드에서 탐색을 계속해서 만나는 노드는 내가 찾은 노드보다 경로의 길이가 길 것이다.
(내가 찾은 리프노드와 1번 노드가 경로의 길이도 같고 둘다 리프노드라면 어느걸 선택해도 문제없다)
2번 노드들의 부모노드 방향으로 따라 올라가다 보면 1번 노드가 나올 것이다.
방금 1번노드들이 최적해가 아닌 이유를 설명했으므로,
그 노드들의 자식노드들인 2번노드들도 최적해가 아님은 당연하다